LLMを使って仮説の自動抽出と分析・可視化を試してみた
きっかけ
LLMの登場により、自然言語の加工・整形や数値化(ベクトル化)が容易になりました。
そこで「自然言語から普遍的な仮説(教訓や法則など)を自動的に抽出・分類することができないか?」と考えました。
仮説を半自動的に抽出できれば、それを可視化することで類似するものを発見・集約できるようになるはずです。
私はメタ認知に強い関心があるので、歴史を扱うポッドキャスト「COTEN RADIO(コテンラジオ)」も愛聴しています。
コテンラジオでは普遍的な法則・教訓などが語られる場面が多く、これらを仮説として見られるようにしたいと考えました。
そこで今回はコテンラジオの書き起こしを用いて仮説の抽出・分析・可視化を試みたので、その記録をまとめます。1
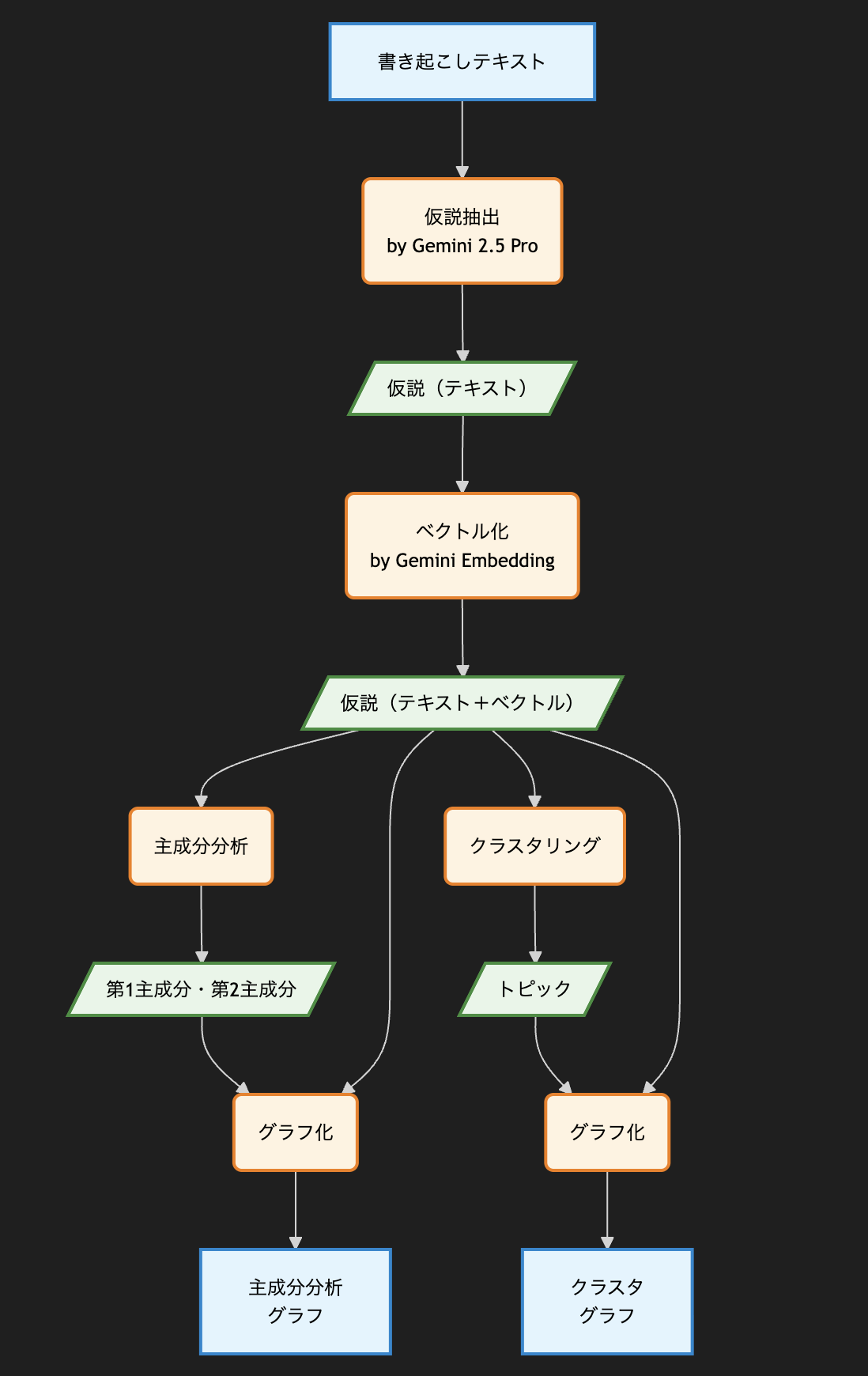
大まかな処理の流れ
分析は、大まかに以下の流れで進めました。
- 書き起こしテキストデータから、Gemini 2.5 Proを使って仮説を抽出
- 抽出された仮説について、Gemini Embeddingを使ってベクトル化
- ベクトル化された仮説を用いて、主成分分析を実行
- 主成分分析の結果をグラフ化
- ベクトル化された仮説を用いて、クラスタリングとトピック抽出を実行
- クラスタリングの結果をグラフ化
書き起こしテキストはコテンラジオの配信486回分を対象にしています。
使用したLLMは以下の通りです。
- Gemini 2.5 Pro:
gemini-2.5-pro-exp-03-25 - Gemini Embedding:
gemini-embedding-exp-03-07- 3072次元ベクトルデータ
分析や可視化に関するスクリプトはGitHubにあります。
事前準備:書き起こしテキストから仮説を抽出
処理の詳細
以下の要項で、Gemini 2.5 Proを使って仮説を抽出しました。
- 「仮説」と、その着想となった「事実」を併せて出力するプロンプトを指定
- 出力形式をJSON形式で指定
- 再現性のためにtemperature=0を指定
実際に用いたシステムプロンプトは以下の通りです。
歴史の具体的な出来事に対してアブダクションを行い、現代においてもいろいろな物事に広く適用可能な仮説を抽出してください。
fact_episodeには、その仮説を導くための具体的な出来事を記載してください
抽出する仮説の数の上限などは特に明示しませんでしたが、1エピソードあたり2〜6個くらい出力できました。
今回は486回分のエピソードを対象に実行し、2607件の仮説が抽出できました。
抽出された仮説の例
例えば日露戦争の1つのエピソードから、抽出された事実と仮説は以下のようになりました。
#203 二〇三高地ヲ陥落セヨ!作戦変更に戸惑う戦線部隊と危機的状況に見る日本人のメンタリティー
| 事実 | 仮説 |
|---|---|
| 日露戦争の旅順攻囲戦において、日本第三軍は、バルチック艦隊到着までの時間的制約、大本営・海軍・世論からの早期攻略の圧力、そして重火器や砲弾の不足という状況下で、準備不十分なまま総攻撃を繰り返し、多大な犠牲を出した。 | 外部からの強いプレッシャーとリソース不足が重なると、準備不足を自覚していても、組織は拙速な行動を強いられ、結果的に失敗を繰り返しコストが増大する可能性がある。 |
| 旅順要塞の防御力に対して火力が不足していることが判明した後も、第三軍は正面攻撃を続けた。これは、当時の軍事的常識に加え、明治天皇からの勅語や国民の期待に応えようとする「頑張り」が、より効果的な(しかし当初はためらわれた)203高地攻略への転換を遅らせた一因とも考えられる。この「戦略で負けているのに精神力で補おうとする」傾向は、現代の組織運営にも見られる課題である。 | 戦略的な欠陥が明らかになっても、「頑張り」や「努力」を過度に重視する文化や価値観は、合理的な戦略転換や撤退の判断を遅らせ、結果的に大きな損失を招く可能性がある。 |
| 旅順攻略において、第三軍は、満州軍総司令部からは「旅順要塞の攻略」を、大本営や海軍からは(バルチック艦隊対策として)「旅順港内の艦隊の無力化」を強く求められた。この目標の齟齬(要塞攻略か、港湾を見下ろす203高地攻略か)が、当初の作戦遂行に混乱を招き、最終的に203高地攻略に転換するまでの意思決定を遅らせた側面がある。 | 複数の上位組織から矛盾する指示や要求が出されると、現場は混乱し、最適な戦略的意思決定が妨げられ、状況への適応が遅れる可能性がある。 |
| バルチック艦隊の接近という時間的制約の中で、「旅順を早期に落とすしかない」という強迫観念が、代替案(例えば最初から203高地攻略に集中するなど)の検討を不十分にさせ、結果的に多大な犠牲を払うことになった。これは、現代のプロジェクト遂行においても、「やるしかない」という状況認識が、より効率的な方法やリスク回避策の検討を妨げるケースと類似する。 | 「〜するしかない」という思考停止は、他の選択肢の検討を放棄させ、より良い解決策を見出す機会を失わせる。特にプレッシャー下ではこの傾向が強まる。 |
特に抽出してほしかったのが4番目の仮説です。
「〜するしかない」という思考停止パターンをちゃんと抽出できています…!
所感
100文字程度のシンプルなプロンプトにもかかわらず、期待以上に仮説を抽出できました。
具体性と抽象性のバランスが取れており、適切な記述が多いように見受けられます。
ただ細部には改善の余地もあり、プロンプトを工夫すればさらに精度を高められそうだと感じました。
分析①:主成分分析の実行と可視化
処理の詳細
以下の要項で主成分分析を行い、散布図にプロットしました。
- 第1主成分と第2主成分を使って可視化
- 散布図ではシリーズ毎に色分けして表示
- 第1主成分と第2主成分の意味づけは、人力で解釈
可視化したグラフ
グラフは以下の通り。全画面で見たい方はこちら。
点にカーソルを合わせると、仮説、事実、シリーズ名が表示されます。
また凡例をクリックすると対象が非表示にでき、凡例をダブルクリックすると対象だけを表示できます。
考察
プロットデータを眺めながらあれこれ考えた結果、第1主成分と第2主成分の軸は以下のように解釈しました。
- 第1主成分(グラフの横軸):個人 ⇔ 組織・システム
- 第2主成分(グラフの縦軸):自由 ⇔ 支配・権力
コテンラジオで扱う内容を考えると、主成分がこのような軸になるのはとても納得感があります。
分析②:クラスタリング&トピック抽出の実行と可視化
処理の詳細
以下の要項でクラスタリングとトピックの抽出・可視化を行いました。
- BERTopicによりトピックを抽出
- UMAPによる次元削減、HDBSCANによるクラスタリング、TF-IDFによるキーワード抽出
- トピック名は、そのトピックの特徴的な単語列をGemini 2.5 Proに与えて半自動的に命名
- 散布図は、トピック毎に色分けして表示
可視化したグラフ
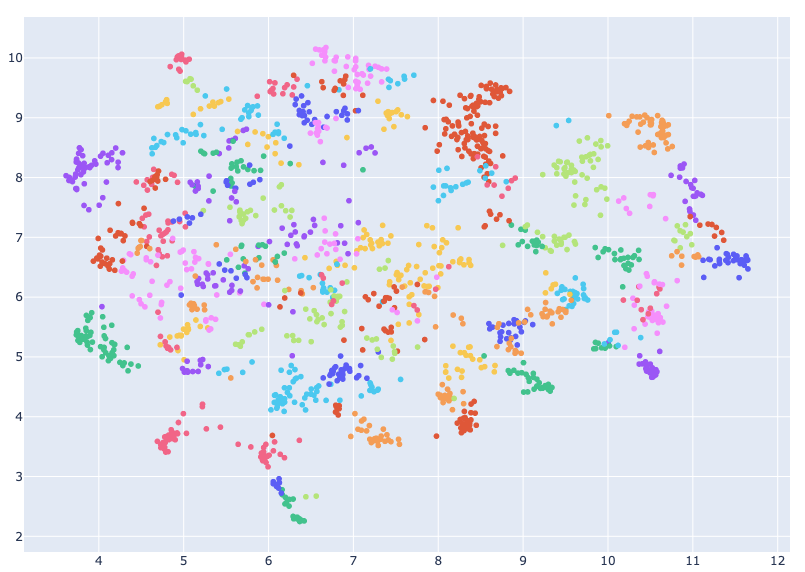
クラスタリングを可視化した結果が以下の通り。全画面で開きたい方はこちら。
点にカーソルを合わせると、仮説、事実、シリーズ名、トピック名が表示されます。
また凡例をクリックすると対象が非表示にでき、凡例をダブルクリックすると対象だけを表示できます。
「Topic -1」は外れ値なので、非表示にして見ることをおすすめします。
考察
外れ値を非表示にすると以下のようになり、うまく分離できていることがわかります。
同じ色が離れて存在するように見えますが、実は異なるトピックで色が使い回されているだけです。(トピックが多すぎるため)
また「Topic 0: 危機下のリーダーシップ」の中でも隣り合う点2つを比べてみます。
すると以下のように似たようなエピソードとなっており、類似するものをうまくグルーピングできているように感じました。


まとめ・所感
自然言語テキストから仮説を抽出し、分析・可視化まで一通り行うことができました。
今回の試行で特に収穫だったポイントは以下の通りです。
LLMによる仮説抽出
期待以上の精度で抽出できました。プロンプト改善により更なる精度向上も期待できそうです。
BERTopic
初めてでしたが生成AIとライブラリのおかげでスムーズに理解・実装できました。アンケート分析等での活用機会も多そうです。
計算リソース
3072次元×2607件のデータセットでも、ローカルPCで十分処理可能でした。
またベクトル化(Embedding)を利用すれば、従来のベクトルデータを対象とする分析技術が活用できます。
生成AIの活用に目が行きがちですが、生成AIを構成する関連技術としてEmbeddingも活用していきたいところです。
ちなみに、あらゆる仮説がうまく生成AIで抽出できるとは考えていません。人間にしかできず、向き合い続ける必要がある領域だと考えています。 ↩︎