AIエージェント用の簡易Leaderboardを作ってみた
最小のAIエージェントは数行で書ける時代ですが、継続的な改善・運用には難しさがあると考えています。
そこで、今回はAIエージェントの改善や評価に有用そうなLeaderboardを作ってみました。
コンセプト
GitHub上で動作する、簡易Leaderboard!
- 最新の結果をGitHub Pagesで閲覧できる
- 各エージェント定義×各ベンチマークタスクを実行できる
- 正解率だけでなく、経過時間や消費トークン数の指標を確認できる
なぜ作ってみようと思ったのか?
AIエージェントの構成要素は、モデル・システムプロンプト・ツールの3つです。
これらの構成要素を着実に改善していくには、以下のような評価を継続的に実行できることが重要だと考えました。
- プロンプトによる差異の比較、チューニング
- ツールの追加・拡充による性能向上・劣化の確認
- モデル間での性能比較や、モデルアップデート時の性能向上・劣化の確認
簡単に使えそうなLeaderboardは探してみたものの、デファクトスタンダードなものはなさそうでした。
しかし構成はおおよそイメージできていたので「それなら既存のものを見つけて理解するよりも作ってしまったほうが早いのでは?」
ということで、このような枠組みを作ることを考えました。
作成にあたっては、以下のような期待を込めています。
- ジュニアエンジニアでもプロンプトを改善したりツールを追加して、エージェントの改善を試みることができる
- タスク定義を追加していくことで、多様なユースケースを定量的に評価することができるようになる
- ゲームのようなランキング形式にすることで楽しく改善できる。ハッカソンにも使えそう
構成
作成したサンプルはGitHubで公開しています。
主要なファイル構成は以下の通りです。
.
├── agents/ # AIエージェントの定義
│ ├── baseline/
│ │ └── agent.py
│ ├── gemini_2_5_flash/
│ │ └── agent.py
│ ├── with_code_executor/
│ │ └── agent.py
│ └── with_google_search/
│ └── agent.py
├── benchmarks/ # ベンチマークタスクの定義
│ ├── task_001.json
│ ├── task_002.json
│ ├── task_003.json
│ ├── task_004.json
│ └── task_005.json
├── results/ # AIエージェント定義毎の評価結果
│ ├── baseline.json
│ ├── gemini_2_5_flash.json
│ ├── with_code_executor.json
│ └── with_google_search.json
├── src/
│ ├── reporter.py # HTMLレポート生成用
│ ├── runner.py # ベンチマーク実行用
│ └── services/
│ ├── cache_manager.py # 評価結果のキャッシュ管理
│ └── evaluator.py # 評価ロジック
└── docs/ (generated) # HTMLレポート
AIエージェント定義
エージェント定義を追加する場合はagents配下にフォルダを作成し、agent.pyを配置します。
これは今回用いたAIエージェントフレームワークがGoogle ADKであるため、そのスタイルに従っています。
もし他のフレームワークを使用する場合は、runnerやreporterの実装を一部差し替える必要があります。
タスク定義
タスク定義を追加する場合は、benchmarks/以下にJSON形式で追加します。このスキーマは独自の形式です。
{
"name": "因数分解(3桁)",
"description": "試行錯誤が必要なタスク",
"query": "989を因数分解して回答してください。回答は数字の小さい順にコンマ区切りで回答してください。",
"expected_answer": "23,43"
}
{
"name": "検索タスク",
"description": "検索が必要なタスク",
"query": "2024年の名目GDPは何兆円?答えだけ回答してください",
"expected_answer": "609"
}
実行方法・実行サンプル
評価を実行するときは以下の流れで実行します。
- AIエージェント定義×ベンチマークタスク定義の組み合わせだけ評価を実行する
- 評価結果はJSON形式で保存する(キャッシュあり)
- JSON結果を集計してHTMLレポートを生成する
ベンチマーク実行
以下によりベンチマークを一通り実行します。
uv run python src/runner.py
都度実行するとモデルの利用料が嵩んでしまうため、通常実行では評価結果がキャッシュされるようにしています。
キャッシュを無効にして実行する場合はオプションを付与するようにしています。
uv run python src/runner.py --ignore-cache
HTMLレポート作成
ベンチマーク実行後、以下によりHTMLレポートを生成します。
uv run python src/reporter.py
これら一連の処理をGitHub Actionsで実行すれば、結果がGitHub Pages上で閲覧できるようになります!1
ベンチマークの実行サンプル
サンプルとして用いたエージェントとベンチマークタスク
今回は以下のエージェントを用意しました。
| # | エージェント | モデル | ツール |
|---|---|---|---|
| 1 | baseline | Gemini 2.5 Flash Lite | なし |
| 2 | with_code_executor | Gemini 2.5 Flash Lite | コード実行 |
| 3 | with_google_search | Gemini 2.5 Flash Lite | Google検索ツール |
| 4 | gemini_2_5_flash | Gemini 2.5 Flash | なし |
ベンチマークタスクは以下の5つを用意しました。(詳細が気になる方はGitHubを参照してください)
- 簡単な計算
- やや複雑な計算
- 因数分解(3桁)
- 因数分解(10桁)
- 検索タスク
実行結果
baselineのエージェントでは、簡単な計算だけ成功しています。

Google検索が実行できるエージェントでは、検索タスク(2024年の日本のGDPを回答)ができるようになりました。
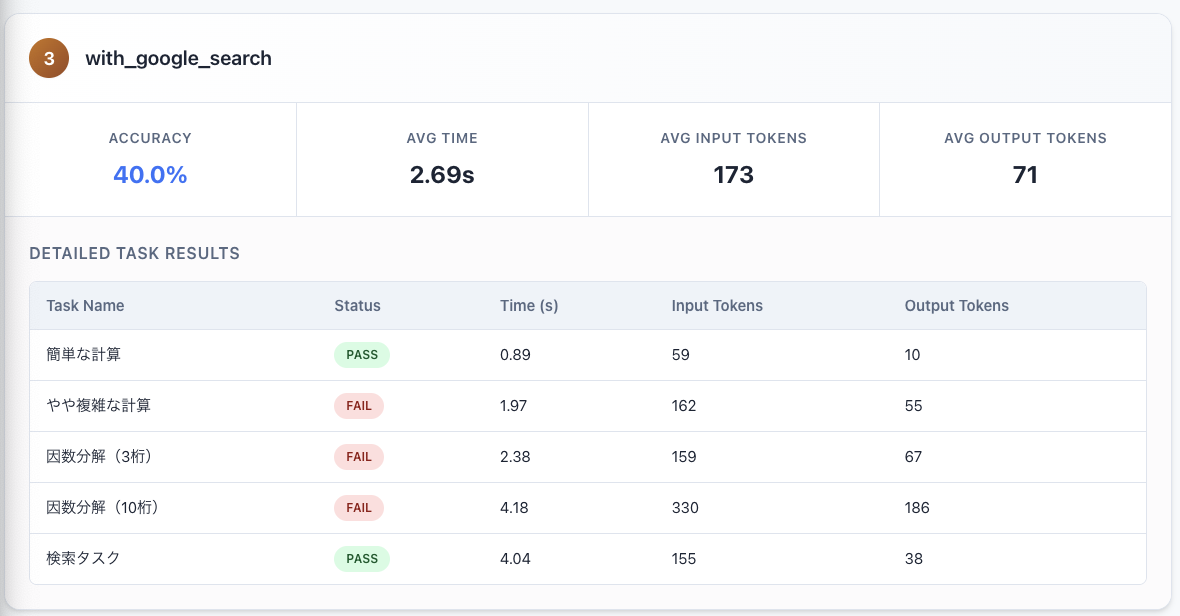
コード実行ができるエージェントでは、複雑な計算や因数分解もできるようになったことがわかります。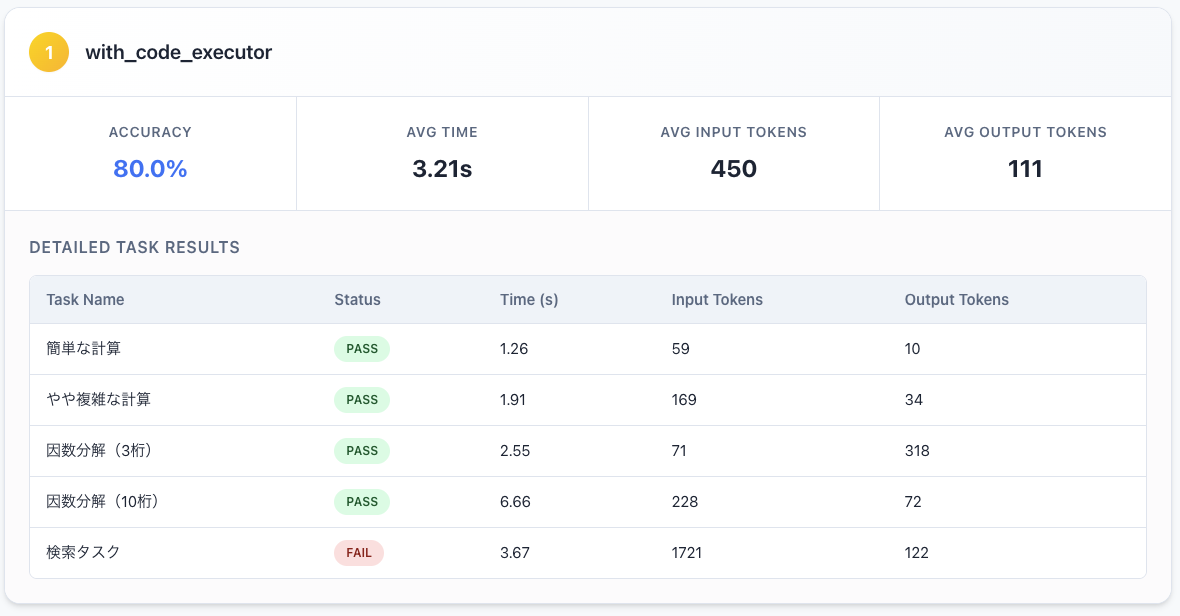
なお、Gemini 2.5 Flashだとツールを使わなくても簡単な因数分解はできるようでした。
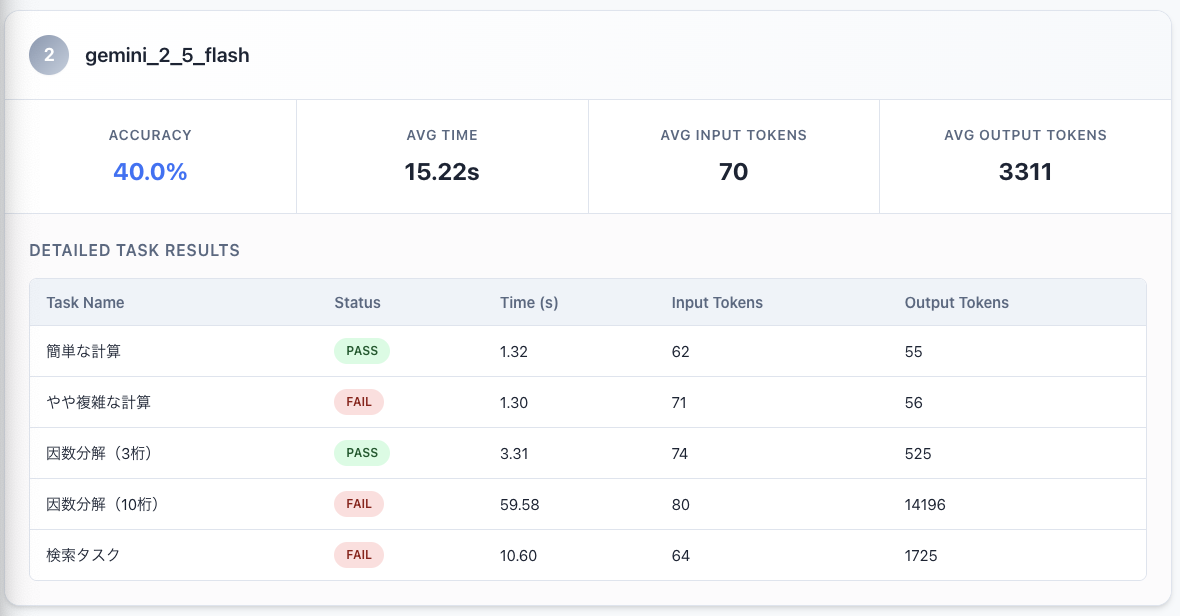
…といった形で、ツールやモデルによるタスクの可否を把握することができます。
やってみてわかったこと・感じたこと
評価ロジックのバリエーションや改善余地
タスクによって正解とする判定条件を変更したくなることが考えられます。
例えば今回は明確な正解が存在するタスクを想定し、出力形式を指示&文言の部分一致で正解とする実装にしました。
明確な正解が存在するタスクでは、以下のような方式を採ると評価しやすくなると考えられます。
- 出力形式を指示する
- 重要な文言の部分一致で正解とする
明確な正解は存在せず、答えが連続値のスコアで表現されるようなタスクでは、例えば以下の方式が考えられます。
- スコアを計算可能なロジックを実装する
- LLM as a Judgeを用いる
- Google ADKに用意されているevalコマンドと同様の評価方式を用いる
使い捨ての簡易フレームワークが容易に作れてしまう時代
このLeaderboardは主にClaude Codeで作成しました。
最低限の機能を作るのにかかった所要時間はおおよそ30分〜1時間くらいでしょうか。
特に実現したい仕様が明確であれば、簡単に作れる時代を実感しました。
既存のフレームワークも探せばあるかもしれませんが、学習コストや認知負荷がハードルになります。
作りたいものが明確であれば、生成AIで作ってしまったほうが早い場面があるということを実感しました。
特に使い捨てのツールであれば、作ってしまったほうが費用対効果が高い場面もあるかもしれません。
将来的には汎用的なAIエージェント評価フレームワークが登場する気もしますが、当面は自作する手もありそうです。
Pytestは採用しづらかった
最初はpytestが使えそうだと考えていましたが、以下の理由からあまりフィットしないことがわかりました。
- 複数の戻り値を定義できないため、処理時間や使用トークン数などの指標の集計が難しい
- Pass/Failの2値しかとれない。もしスコア(連続値)を表現したくなってもできない
そのためベンチマークの実行結果をJSONで保存し、JSONからHTMLレポートを生成する方式を採りました。
まとめ
というわけで、AIエージェント用の簡易Leaderboardを作ってみたお話でした。
AIエージェントは運用しながら継続的な改善をすることが最も重要なポイントだと考えていますが、このような枠組みがあれば取り組みやすそうだという実感を持ちました。
業務で必要となったときにはこのエッセンスを活用していきたいと思います。
免責事項:
このフレームワークを継続的に開発・保守する予定はありません。あくまでサンプルコードとして捉えてください。
この着想をベースに自作したり発展させることに関しては、もちろんご自由にどうぞ!
GitHub Actionsで実行された場合、評価結果のキャッシュは次回実行に反映される構成にはなっていません(記事執筆時点) ↩︎