生成AIで生成タスクを扱うのは難しいという話
半年前から感じていたことについて、最近コーディングエージェントを活用する中で確信が強くなったのでまとめることにした。
生成AIで扱うタスクを3つの要素で捉えてみる
生成AIを活用するタスクは、情報量の変化に着目すると、以下の3つに大別できる。
(ここでの『情報量』とは文字数や情報エントロピーではなく、入力が持つ意味内容の範囲や事実を指す)
- ①情報生成:入力に対して情報量を増やす
- ②情報変換:入力に対して情報量を変化させない。意味を保ったまま表現形式を変換する
- ③情報抽出:入力に対して情報量を減らす。情報を削ぎ落とし、必要な情報だけを取り出す
もちろん、あらゆるタスクがこの3つのどれか一つにきれいに分類できるわけではない。 しかし、タスクごとに「どの特性が強いか」を意識することが、生成AIをうまく活用する上で重要になる。
生成AIが得意なのは「情報変換」と「情報抽出」
経験上、生成AIが最も価値を発揮するのは「②情報変換」と「③情報抽出」のタスクである。 これは「得意」というより「構造的に向いている」と表現するほうが適切かもしれない。
これらの要素が強いタスクの例を挙げる。
- 要約:WebページやPDFなどのテキストの内容を、要約する
- 解説:WebページやPDFなどのテキストの内容を、わかりやすく解説する
- 翻訳:自然言語を他の言語へ翻訳する
- コーディング:自然言語などで記述された仕様に基づき、ソースコードを書く
- 整形:議事録作成など、テキストを所定のフォームへ落とし込む
これらのタスクを情報量の面から考察すると、以下のようになる。
- 要約:ほぼ③情報抽出のみ。
- 解説:②情報変換のみ。一見すると増えているようで、本質的な意味や情報量は増えない
- 翻訳:ほぼ②情報変換のみ。ただし情報量が減少するケースもある1
- コーディング:翻訳タスクと同様2。ただし①情報生成の要素が加わるケースも多い
- 整形:②情報変換と③情報抽出の組み合わせ。フォームに沿う情報だけを抽出・変換し、不必要な情報は削ぎ落とされる
なぜ「情報生成」は難しいのか
一方で「①情報生成」のタスクは、本質的な難しさを抱えている。
それは情報生成には無数の選択肢が存在するため、適切な前提を与えなければ、期待する出力を得ることが困難ということだ。
この関係は、探索問題における「探索空間」と「解空間」の概念で説明できる。
- 探索空間:問題を解く際に検討される可能性のある全候補の集合。LLMが生成しうる、ほぼ無限の回答パターンに相当
- 解空間:探索空間の中で、ユーザーが求めている正解(単語列)の集合。要求水準が高いほどこの空間は狭くなる
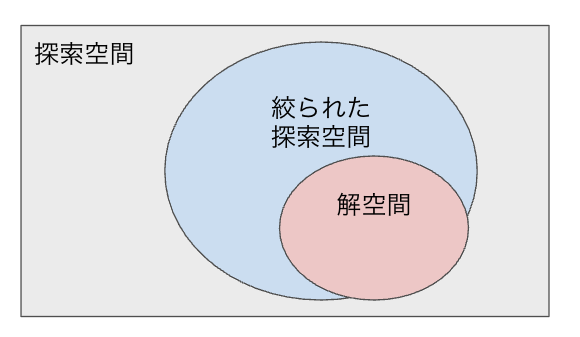
この探索問題では、次のような特徴がある。
- 良い前提(プロンプト)は、広大な探索空間を限定し、解空間へ導いてくれる
- 悪い前提は、探索空間を十分に絞れない。最悪の場合、解空間を含まない領域を探索させてしまう
- 探索空間を解空間とほぼ一致させない限り、最終的な出力は確率論的なもの、すなわち「生成AIガチャ」になる。
解空間が広ければガチャの当たりは出やすいが、解空間が狭い場合は当たりを引く確率は著しく低下する。
これこそが「①情報生成タスクが構造的に抱える難しさ」の一つだと考えている。
「情報生成」タスクとの向き合い方
この構造的な難しさに対し、取れる戦略は2つある。
戦略①:できるだけ情報量を増やさないタスクに落とし込む
「生成AIに数学問題を解かせたら間違えた」という話を聞いたことがある。
これは答えを生成させる①情報生成タスクであり、LLMが苦手とする論理的推論も相まって失敗しやすい。
一方で「数学の問題と解答を与えて解説させたら秀逸だった」という話がある。
これは問題と解答をインプットとして「②情報変換」のタスクに落とし込むことで、成功率が高くなったと言えるだろう。
このように、可能な限りタスクを「情報変換」や「情報抽出」に寄せられないか検討することが、生成AI活用の第一歩となる。
戦略②:探索空間を限定し、ガチャの確率を上げる
どうしても情報生成タスクと向き合わなければいけない場面は存在する。
そのようなときは、まずLLMが扱う問題の探索空間を絞り込める入力を与えること。そして、生成AIガチャをひたすら回すこと。
さらに生成AIガチャの出力結果を自動評価できる環境が整っていれば理想的だ。
いつも自身がLLMを使って問題を解くときは、LLMの探索空間を絞って解空間へ近づけることを考えている。
適切なコンテキストを与えることで探索空間を限定することができ、望ましい解を得られる可能性が高くなる。
コーディングエージェントはなぜ難しいのか
コーディングタスクにおける情報生成の度合い
コーディングエージェントは、PoC(技術検証)のような場面では非常に心強い。
しかし、プロダクトコード開発のような厳密さが求められる場面では、途端に心許なくなる。
この差は、まさに「探索空間の絞り込みやすさ」と「解空間の広さ」の違いに起因する。
コーディングエージェントでよくみかける問題は、以下のような内部仕様や非機能要件に関するものだ。
- 内部仕様:クラスや関数の設計、命名、共通化、技術的なエラーハンドリングなど
- 非機能要件:セキュリティ、パフォーマンスなど
両者の違いを整理すると、以下のようになる。
| 比較項目 | PoC | プロダクトコード |
|---|---|---|
| 要求水準 | ◯:外部仕様のみでOK | △:外部仕様、内部仕様、非機能要件が必要 |
| 要求の言語化 | ◯:外部仕様は言語化しやすい | △:内部仕様や非機能要件は言語化しにくい |
| 探索空間 | ◯:言語化しやすく、探索空間を絞りやすい | △:言語化しにくく、探索空間を絞りにくい |
| 解空間 | ◯:要求水準が低いので、広い | △:要求水準が高いので、狭い |
このようにPoCでは探索空間を絞りやすく解空間も広いが、プロダクトコードでは探索空間を絞りにくく解空間も狭い。
その結果、プロダクトコード開発は「①情報生成」の性質が非常に強くなり、AIにとって極めて難しいタスクとなる。
これこそが、コーディングエージェントに対する期待と現実のギャップを生む根本原因だろう。
プロダクト開発でコーディングエージェントを活用するには
プロダクトコードでは要求水準が高いため、「①情報生成タスク」の性質が強くなることは避けられない。
しかし探索空間さえ絞り込めば、純粋な②情報変換タスクに近づけることができる。
探索空間を狭める仕組みや、生成AIガチャを効率的に引くための仕組みとしては、以下が重要になる。
- 良質なコンテキストを与える:言語化しにくい内部仕様は、参考になりそうな既存コードを読み込ませる
- ルールを明示する:カスタムルールに記述しておくことで、毎回入力に含められるようにする
- 評価を自動化する:Linterやテストコードを整備し、生成されたコードを高速に判定できるようにする
これはコーディングエージェント活用の文脈でよく語られることだが、前述の内容とも整合している。